Analyzing a Grammar Ambiguity Using Variables and Trees
Let’s look at a grammatically ambiguous sentence fragment by me. This is a simple example of analyzing text, which is common philosophical activity. For context, I wrote CF newsletter titles and descriptions:
We’ll analyze this text:
Infrequent updates and links to Elliot's work
This is a sentence fragment because there’s no verb. It’s just a noun phrase indicating what’s in the newsletter.
Based on grammar, this phrase could have two different meanings. Do you see what they are?
To resolve the ambiguity, readers must consider the content and context. They have to make a judgment about what interpretation makes sense. This requires critical thinking.
When reasonable readers can’t reach a decisive conclusion about the meaning, then it’s considered ambiguous. In this case, I don’t really consider it ambiguous. But it is ambiguous based only on grammar rules, so I call it “grammatically ambiguous”.
To show the ambiguity, I’ll use two tools: trees and algebra. I’ve said these are prerequisites for CF (along with grammar). This will illustrate a way they’re useful.
First, we’ll use two variables so we can focus on the relevant parts of the sentence.
X = “updates”
Y = “links to Elliot’s work”
Using substitution, we now have:
Infrequent X and Y
Now we can look at the two grammatically-possible meanings, in a precise way, using grammar trees:
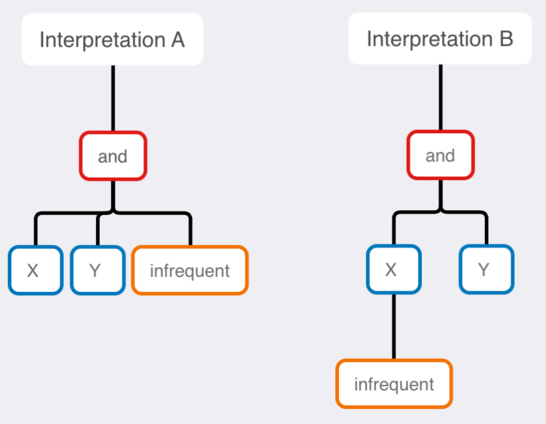
The phrase is grammatically ambiguous because there are two different grammar trees that have no grammatical error. There is no rule of grammar which prevents either one from being correct.
The issue is whether the modifier “infrequent” applies to X or to the group “X and Y”. This specific ambiguity is common in English. There’s often a modifier followed by a group, in which case readers have to figure out if the modifier applies to the whole group or just the first element of the group.
It’d be misleading to begin a brief newsletter description with “infrequent” if there were two types of emails but only one was infrequent (unless there was a second modifier word explicitly saying that the second type is more frequent). It’d be bad to send out a bunch of emails then abuse to ambiguity to say “I never said Y would be infrequent”. It’s more reasonable to read it as both X and Y being infrequent. It’s also reasonable to interpret it as saying emails will contain X and/or Y (often both), rather than as saying there will be two separate types of emails, but that interpretation again requires some thinking, not just applying grammar rules.
Knowing grammar rules helps do some analysis and helps avoid some errors, but good judgment is needed too. Here are two example interpretation trees which violate the rules of grammar, so grammar knowledge lets us rule them out:
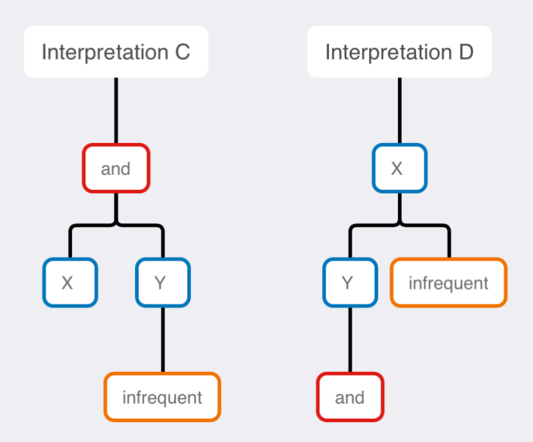
Interpretation C could be a valid grammar tree, but it doesn’t fit the text we’re analyzing. Interpretation D couldn’t be a valid grammar tree because “and” has no children.
Discussing substitution again, another good option is using the head word from each phrase as a variable, so that each phrase you want to reduce becomes a single word instead of a letter. Since “updates” is already a single word, we wouldn’t do anything with it. We’d just define one variable: links = “links to Elliot’s work”. Then “links” is a variable representing a phrase, but it’s also, simultaneously, a meaningful word. That duality can be helpful or confusing, so I use this technique sometimes but not other times. Using one word long variable names reduces the number of tree nodes just as well as using one letter long variable names.
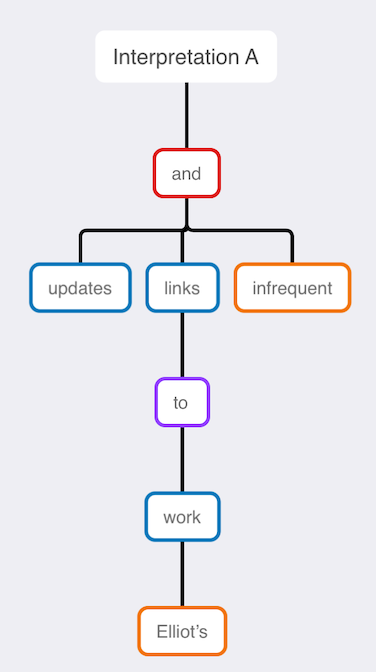
After you make progress on your analysis, substituting in reverse, to add words back into the text you’re analyzing, can help you apply your conclusions to the original subject matter. Here’s the correct grammar tree with the variables substituted out:
Discussion